
ある列の値でグルーピングした中で別の項目値が最大の行のリストを作る、非常に良くある処理です。あまりにも頻出しすぎて何度かいたかもうわかりません。
■ C# で書くとこんな感じのやつです
分かりやすく C# で書くとこんな感じの一文の処理です。
var maxs = values?.GroupBy(x => x.A).Select(x => x.OrderByDescending(m => m.B).First()).ToArray();
データの生成や結果の出力などを含めて実行できるコードにするとこんな感じになります。
// データ const string json = @"[ {""A"": 1, ""B"": 1} , {""A"": 2, ""B"": 2} , {""A"": 2, ""B"": 3} , {""A"": 3, ""B"": 3} , {""A"": 3, ""B"": 4} , {""A"": 3, ""B"": 5} ]"; var values = System.Text.Json.JsonSerializer.Deserialize<M[]>(json); // A の値ごとの B が最大のものを求める var maxs = values?.GroupBy(x => x.A).Select(x => x.OrderByDescending(m => m.B).First()).ToArray(); // 結果を出力 Console.WriteLine(string.Join(Environment.NewLine, maxs?.Select(x => $"{x.A}: {x.B}") ?? Enumerable.Empty<string>())); // 実行結果 // 1: 1 // 2: 3 // 3: 5 // データクラス record M(int A, int B);
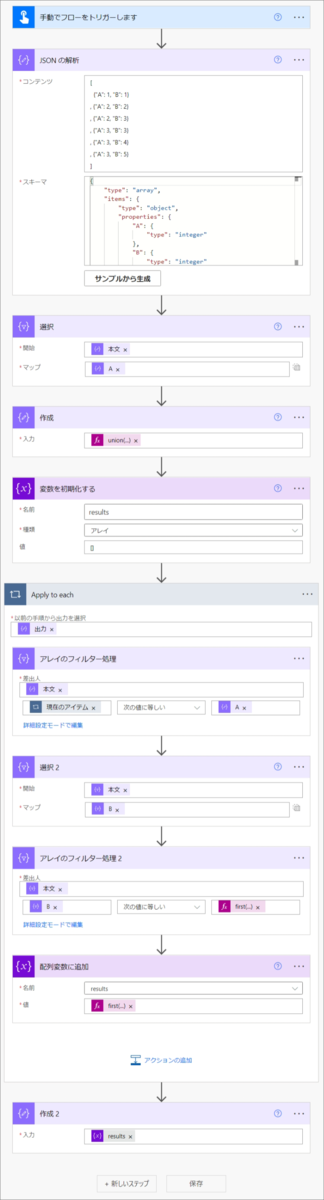
■ Power Automate でフローを組むと
こんな感じになります。
実行結果はこんな感じ。
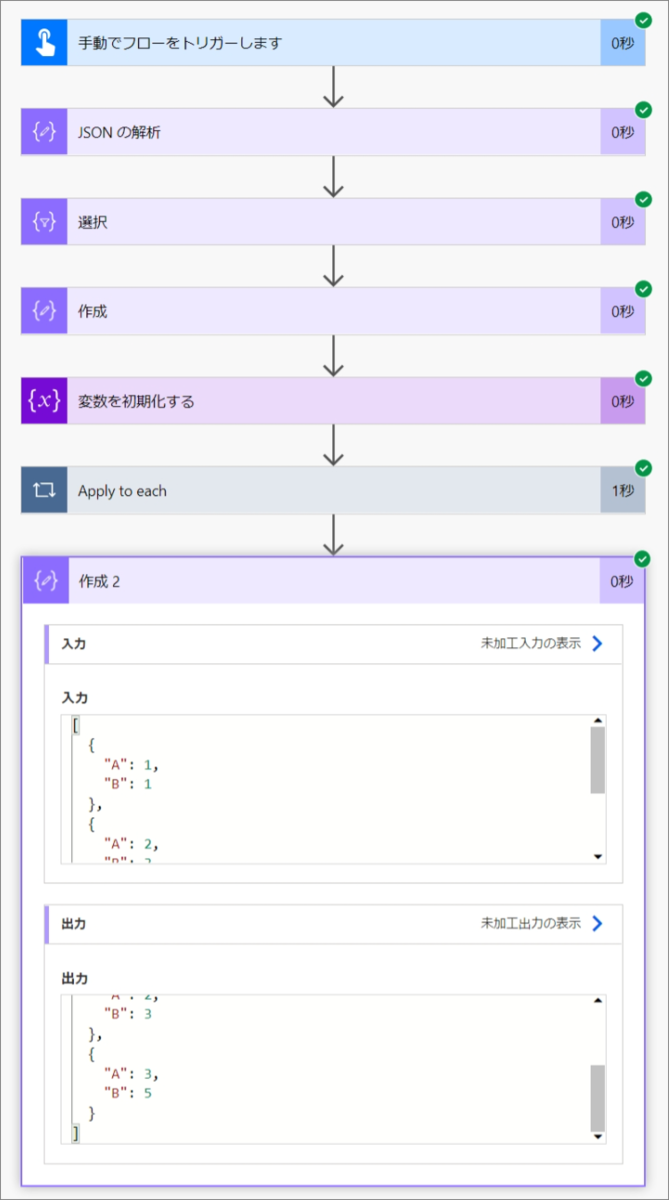
最後の出力は次のようになります。
[ { "A": 1, "B": 1 }, { "A": 2, "B": 3 }, { "A": 3, "B": 5 } ]
■ C# で書くと
フローの画像を見てみ把握しにくいと思いますので、C# で同じように書いてみました。
一文が一アクションになるように書いています。
// データ const string json = @"[ {""A"": 1, ""B"": 1} , {""A"": 2, ""B"": 2} , {""A"": 2, ""B"": 3} , {""A"": 3, ""B"": 3} , {""A"": 3, ""B"": 4} , {""A"": 3, ""B"": 5} ]"; var JSONの解析 = System.Text.Json.JsonSerializer.Deserialize<M[]>(json); // A の値ごとの B が最大のものを求める var 選択 = JSONの解析?.Select(X => X.A).ToArray(); var 作成 = Enumerable.Union(選択, new int[0]).ToArray(); List<M> 配列変数 = new(); foreach(var item in 作成) { var アレイのフィルター処理 = JSONの解析.Where(x=> item == x.A).ToArray(); var 選択2 = アレイのフィルター処理.Select(x => x.B).ToArray(); var アレイのフィルター処理2 = アレイのフィルター処理.Where(x => x.B == 選択2.OrderBy(m => m).Reverse().First()); 配列変数.Add(アレイのフィルター処理2.First()); } // 結果を出力 Console.WriteLine(string.Join(Environment.NewLine, 配列変数?.Select(x => $"{x.A}: {x.B}") ?? Enumerable.Empty<string>())); // 実行結果 // 1: 1 // 2: 3 // 3: 5 // データクラス record M(int A, int B);
■ C# で普通に書いたコードとの比較
分かりやすいよう、データ加工の処理の部分だけを抜き出して C# で普通に書いたときのコードと比較しますね。
C# で普通に書いたコード
var maxs = values?.GroupBy(x => x.A).Select(x => x.OrderByDescending(m => m.B).First()).ToArray();
Power Automate のフローと同じ手続きを C# で再現したコード
var 選択 = JSONの解析?.Select(X => X.A).ToArray(); var 作成 = Enumerable.Union(選択, new int[0]).ToArray(); List<M> 配列変数 = new(); foreach(var item in 作成) { var アレイのフィルター処理 = JSONの解析.Where(x=> item == x.A).ToArray(); var 選択2 = アレイのフィルター処理.Select(x => x.B).ToArray(); var アレイのフィルター処理2 = アレイのフィルター処理.Where(x => x.B == 選択2.OrderBy(m => m).Reverse().First()); 配列変数.Add(アレイのフィルター処理2.First()); }
■ フローの設定
フローの画像では設定している関数、式等わからないのでコードを書いていおきます。
JSON の解析
{ "inputs": { "content": [ { "A": 1, "B": 1 }, { "A": 2, "B": 2 }, { "A": 2, "B": 3 }, { "A": 3, "B": 3 }, { "A": 3, "B": 4 }, { "A": 3, "B": 5 } ], "schema": { "type": "array", "items": { "type": "object", "properties": { "A": { "type": "integer" }, "B": { "type": "integer" } }, "required": [ "A", "B" ] } } } }
選択
{ "inputs": { "from": "@body('JSON_の解析')", "select": "@item()['A']" } }
作成
{ "inputs": "@union(body('選択'), json('[]'))" }
変数を初期化する
{ "inputs": { "variables": [ { "name": "results", "type": "array", "value": [] } ] } }
以下 Apply to each の中
Apply to each
以前の手順から出力を選択: @{outputs('作成')}
アレイのフィルター処理
{ "inputs": { "from": "@body('JSON_の解析')", "where": "@equals(items('Apply_to_each'), item()['A'])" } }
選択
{ "inputs": { "from": "@body('アレイのフィルター処理')", "select": "@item()?['B']" } }
アレイのフィルター処理
{ "inputs": { "from": "@body('アレイのフィルター処理')", "where": "@equals(item()?['B'], first(reverse(sort(body('選択_2')))))" } }
配列変数に追加
{ "inputs": { "name": "results", "value": "@first(body('アレイのフィルター処理_2'))" } }
Apply to each 終了
作成
{ "inputs": "@variables('results')" }
■ フロー概要
フローの概要は次のようになっています。
- 選択 アクションでグルーピングする A 列の値だけの配列を作る
- そこから union 関数を利用して重複を取り除く
- 重複を取り除いた配列を Apply to each で繰り返し処理
- アレイのフィルター処理 で A 列が Apply to each のその回のものを取り出す (※1)
- そこから 選択 で B 列の値だけの配列を作る
- その配列を sort 関数や first 関数を使用して (今思えば last 関数を使っても良かった) 最大のものを算出し、※1 から アレイのフィルター処理 で B が最大のものを取り出す
- 取り出したもの (同順一位を考慮して first 関数にかけたもの) を 配列変数に追加
- Apply to each が終わった後の 配列変数が 結果
です。
■ かんたんですね
かんたんですね。